Bienvenidos a Codea+ 2022
Presentamos la nueva versión del corpus CODEA+ 2022.
CODEA+ 2022 recoge 4023 documentos y 7726 facsímiles (frente a los 2500 documentos y 3427 fotografías de CODEA+2015). El límite temporal se amplía de 1800 a 1900. Incluye también importantes mejoras en la recuperación
de los datos, ya que se ha lematizado y categorizado gramaticalmente más de un 90% del léxico que contiene. Además de la nueva posibilidad de buscar o filtrar por materias o por la ocupación del escribano, la lematzación ha permitido también clasificar nocionalmente todo el léxico de CODEA+2022 en una taxonomía cuyo primer nivel
corresponde a los conceptos de 1. Universo, 2. Mente e individuo y 3. Sociedad, a los que se subordinan otras clases de segundo nivel y a estas las de un tercero, llegando finalmente a los lemas y de estos a los documentos que recogen dichos conceptos. Esta ontología se está integrando en estos momentos en la página de consulta del corpus y estará disponible en breve.
Puede seguir consultándose la versión CODEA+ 2015 siguiendo este enlace: CODEA+ 2015.
El corpus CODEA (Corpus de Documentos Españoles Anteriores a 1900)
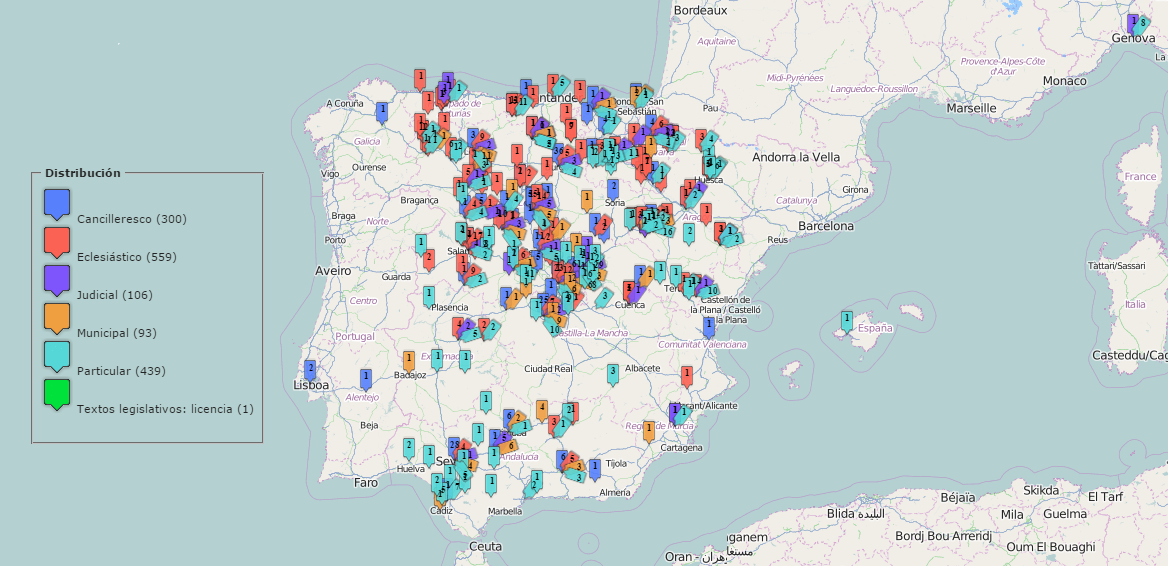
es una herramienta imprescindible para los estudiosos de la historia de la lengua, la dialectología diacrónica y la geografía lingüística, para paleógrafos, interesados por la historia general, de la vida privada y las mentalidades, y para todos aquellos que busquen información de carácter local o de cualquier otro tipo sobre el pasado antiguo y reciente. CODEA ofrece en su estado actual 4023 documentos en español de toda la geografía peninsular del español y de diferentes registros (desde la Cancillería a las notas de manos inhábiles). Los textos se presentan en edición triple (facsimilar, paleográfica y crítica). CODEA es un corpus de libre acceso, fiable y citable, con transcripciones rigurosas directamente realizadas por el equipo elaborador. Las lecturas ofrecidas se pueden comprobar en los facsímiles. CODEA permite búsquedas simples y complejas, filtradas por varios parámetros (fechas, lugares, tipologías diversas, género, etc.). Los resultados de las búsquedas pueden exportarse a lista, gráfico y mapa. CODEA+ 2022 se convierte así en un verdadero Atlas Lingüístico Diacrónico y Dinámico del Español.
 {h. 1r} [encabezamiento: la Reyna] 1 asistente alcaldes alguazil Regidores Caualleros Jurados & omes buenos dela muy2 noble & muy leal çibdad de toledo Vy ...
{h. 1r} [encabezamiento: la Reyna] 1 asistente alcaldes alguazil Regidores Caualleros Jurados & omes buenos dela muy 2 noble & muy leal çibdad de toledo Vy vuestra carta & oy lo que de parte de vos otros en nonbre3 desa dicha muy noble çibdad me dixeron estos dos Regidores & dos Jurados dadores dela 4 presente /los quales ljeuan el conçierto que Aca paresçio para bien & yguala deste de5bate sobre que vinjeron / afectuosa mente vos Ruego les sea dada entera fee y por 6 serujcio del Rey mj Sennor & mjo & por Redençion delas vexaçiones desa çibdad E 7 paçificaçion della Acabsa delo qual yo me quise ynterponer en esta yguala / que a vos 8 otros plega que estas cosas sean Atajadas segun de Aca va Apuntado y alla vereys pues 9 que asy paresçio en mj consejo & alos dichos vuestros mensajeros que estaua Razonable mente 10 para bjen delas partes lo qual mucho vos agradesçere y terne en serujçio descalona A 11 siete de mayo del xxij 12 [firma: yo la reyna] 13 Por mandado dela rreina diego de saldanna | [rúbrica]
{h. 1r} [encabezamiento: la Reyna] 1 asistente alcaldes alguazil Regidores Caualleros Jurados & omes buenos dela muy2 noble & muy leal çibdad de toledo Vy ...
{h. 1r} [encabezamiento: la Reyna] 1 asistente alcaldes alguazil Regidores Caualleros Jurados & omes buenos dela muy 2 noble & muy leal çibdad de toledo Vy vuestra carta & oy lo que de parte de vos otros en nonbre3 desa dicha muy noble çibdad me dixeron estos dos Regidores & dos Jurados dadores dela 4 presente /los quales ljeuan el conçierto que Aca paresçio para bien & yguala deste de5bate sobre que vinjeron / afectuosa mente vos Ruego les sea dada entera fee y por 6 serujcio del Rey mj Sennor & mjo & por Redençion delas vexaçiones desa çibdad E 7 paçificaçion della Acabsa delo qual yo me quise ynterponer en esta yguala / que a vos 8 otros plega que estas cosas sean Atajadas segun de Aca va Apuntado y alla vereys pues 9 que asy paresçio en mj consejo & alos dichos vuestros mensajeros que estaua Razonable mente 10 para bjen delas partes lo qual mucho vos agradesçere y terne en serujçio descalona A 11 siete de mayo del xxij 12 [firma: yo la reyna] 13 Por mandado dela rreina diego de saldanna | [rúbrica]
{h. 1r} La Reina. 1 Asistente, alcaldes, alguazil, regidores, cavalleros, jurados e omes buenos de la muy 2 noble e muy leal cibdad de Toledo; vi ...
{h. 1r} La Reina. 1 Asistente, alcaldes, alguazil, regidores, cavalleros, jurados e omes buenos de la muy 2 noble e muy leal cibdad de Toledo; vi vuestra carta e oí lo que de parte de vosotros, en nombre 3 d'esa dicha muy noble cibdad, me dixeron estos dos regidores e dos jurados dadores de la 4 presente, los cuales lievan el concierto que acá pareció para bien e iguala d'este debate 5 sobre que vinieron. Afectuosamente vos ruego les sea dada entera fee y por 6 servicio del rey mi señor e mio e por redención de las vexaciones d'esa cibdad e 7 pacificación d'ella, a cabsa de lo cual yo me quise interponer en esta iguala que a vosotros 8 plega que estas cosas sean atajadas según de acá va apuntado y allá veréis, pues 9 que así pareció, en mi consejo e a los dichos vuestros mensajeros, que estava razonablemente 10 para bien de las partes, lo cual mucho vos agradeceré y terné en servicio.
D'Escalona, a 11 siete de mayo del XXII. 12 Yo la Reina. 13 Por mandado de la reina, Diego de Saldaña.

De cada documento se ofrece una triple presentación: (1) transcripción paleográfica, (2) presentación crítica y (3) facsímil. Los
criterios de edición seguidos son los de la Red Internacional
CHARTA. En la transcripción paleográfica el desarrollo de las abreviaturas se marca en cursiva (v
ezino); se reflejan las grafías del documento
(hauer, auer, haver; dezir, decir, dezir); se reflejan mayúsculas y minúsculas según el uso del documento
(Rio, dios, Juan lopez); se refleja la puntuación del documento. En la presentación crítica se desarrollan las abreviaturas sin dejar constancia (vezino); se regularizan las grafías sin trascendencia fonética
(vua > uva, ssaber > saber); se regula el uso de mayúsculas y minúsculas para marcar la sintaxis y para distinguir el nombre propio del común:
el concejo, don Fernando); se introduce la tilde según las reglas académicas para marcar la prosodia antigua (med.
reína, vío); mediante la puntuación se refleja la sintaxis antigua.
Los resultados de cada consulta se ofrecen cuantificados de acuerdo con cuatro clases de parámetros:
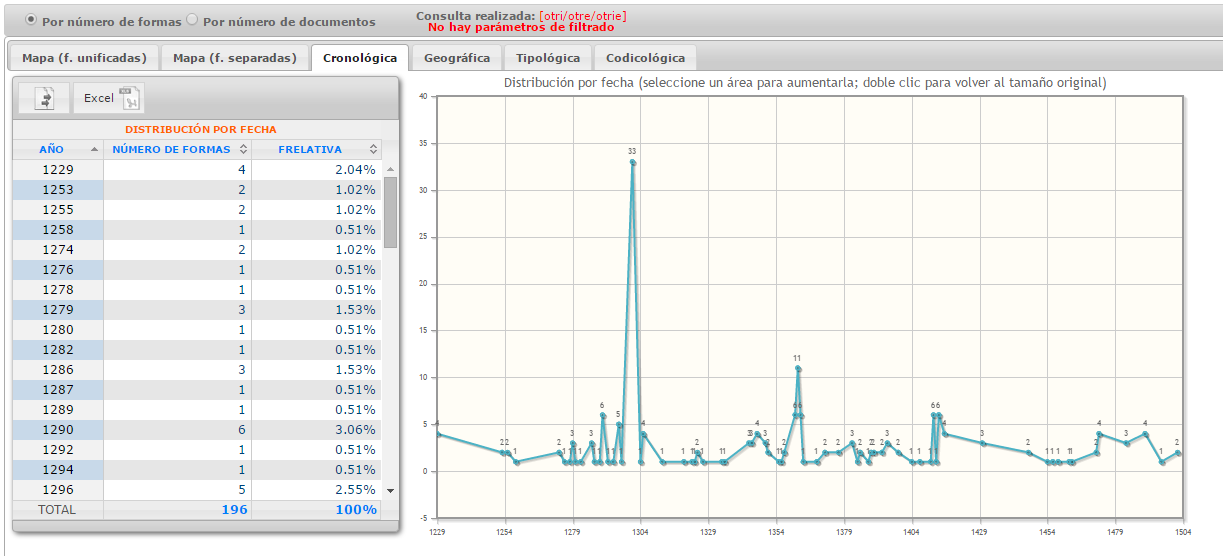
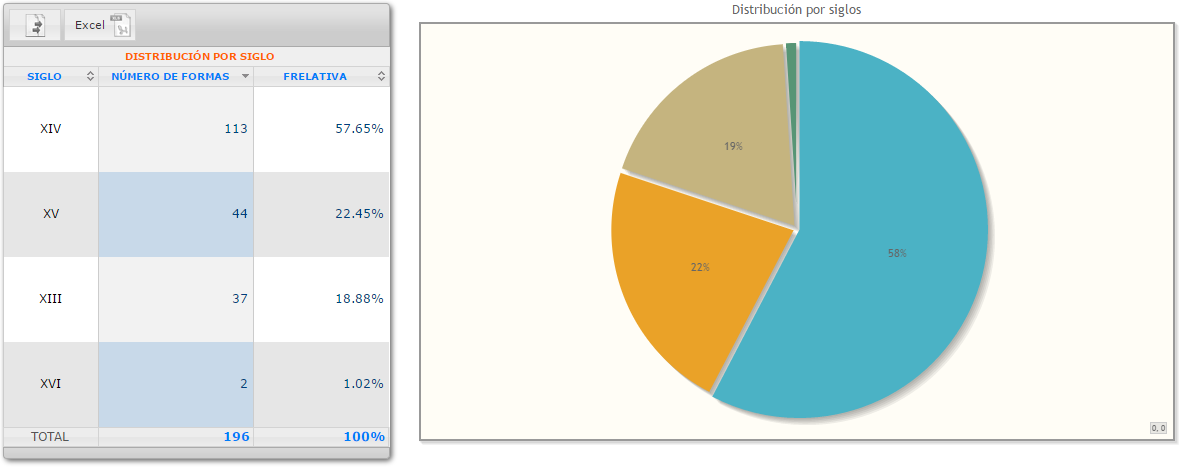
 Cronológico: las fechas de emisión constituyen los puntos de un gráfico lineal; se ofrece también el número de formas buscadas por países, provincias y población.
Cronológico: las fechas de emisión constituyen los puntos de un gráfico lineal; se ofrece también el número de formas buscadas por países, provincias y población.
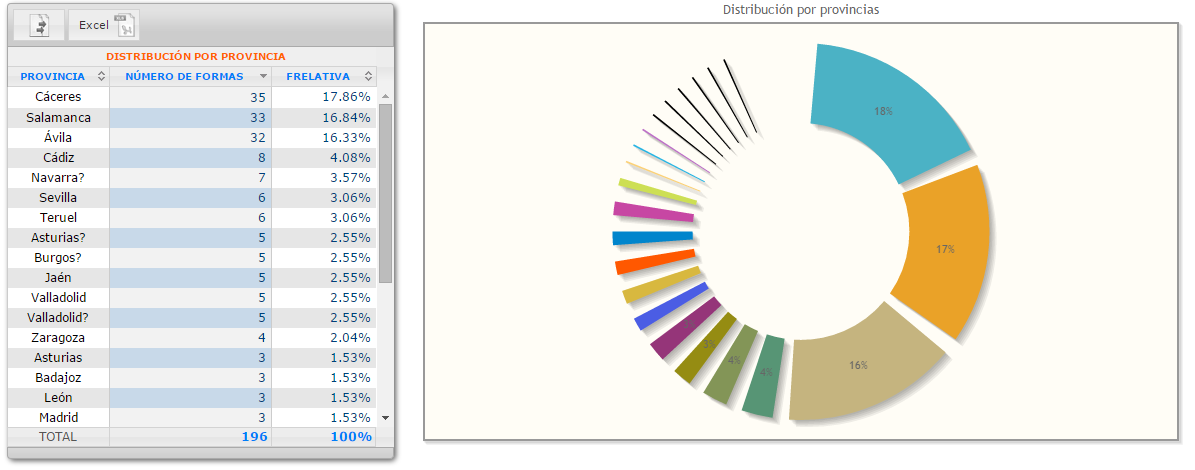
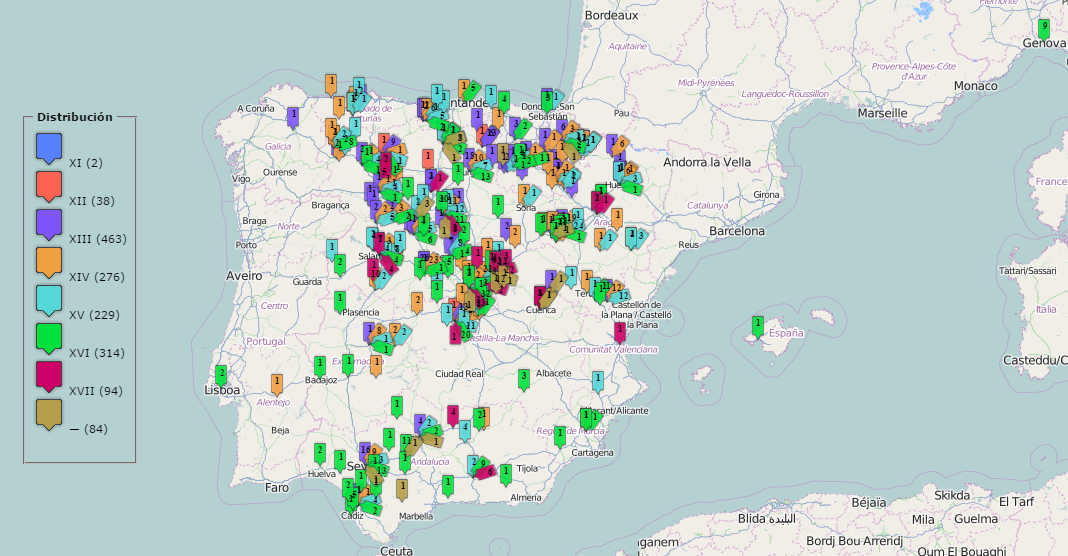
 Geográfico: muestra la distribución de las formas buscadas por países, provincias y población.
Geográfico: muestra la distribución de las formas buscadas por países, provincias y población.
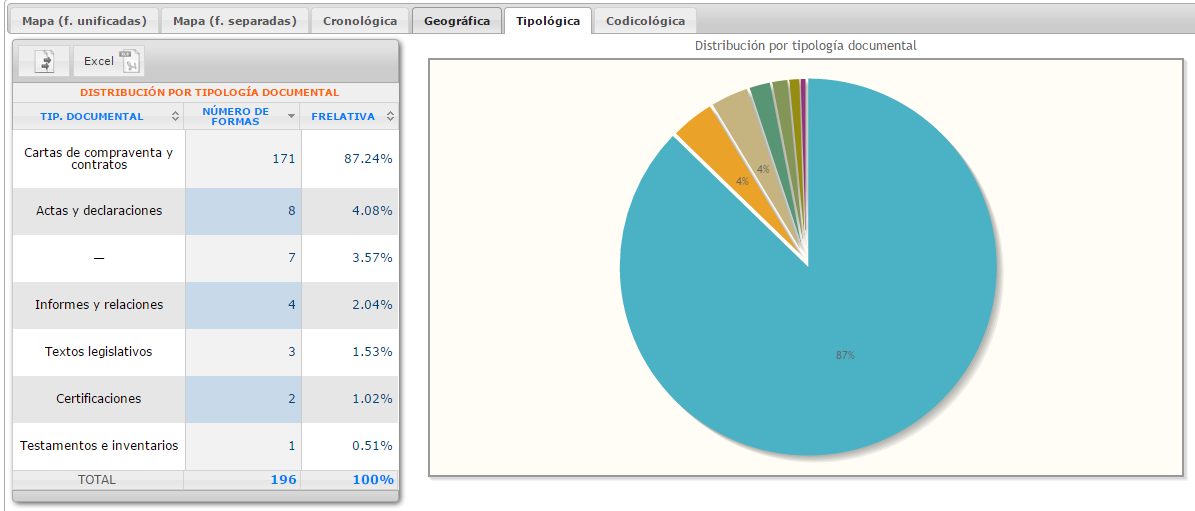
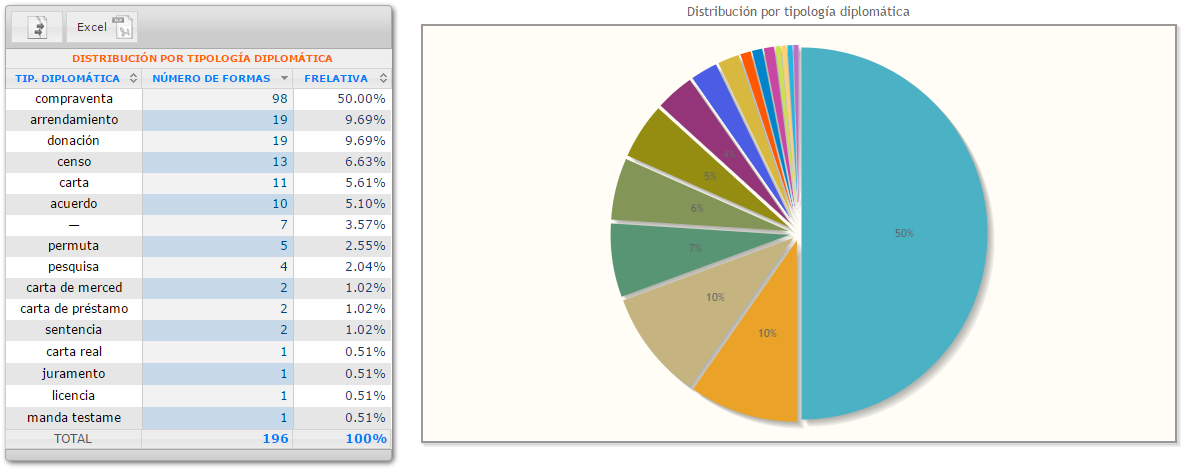
 Tipológico: muestra gráficos del número de apariciones por tipología documental, tipología diplomática, ámbito de emisión (ver Documentos > Clasificación) y por participación femenina (ver Documentos > Participación de mujeres).
Tipológico: muestra gráficos del número de apariciones por tipología documental, tipología diplomática, ámbito de emisión (ver Documentos > Clasificación) y por participación femenina (ver Documentos > Participación de mujeres).
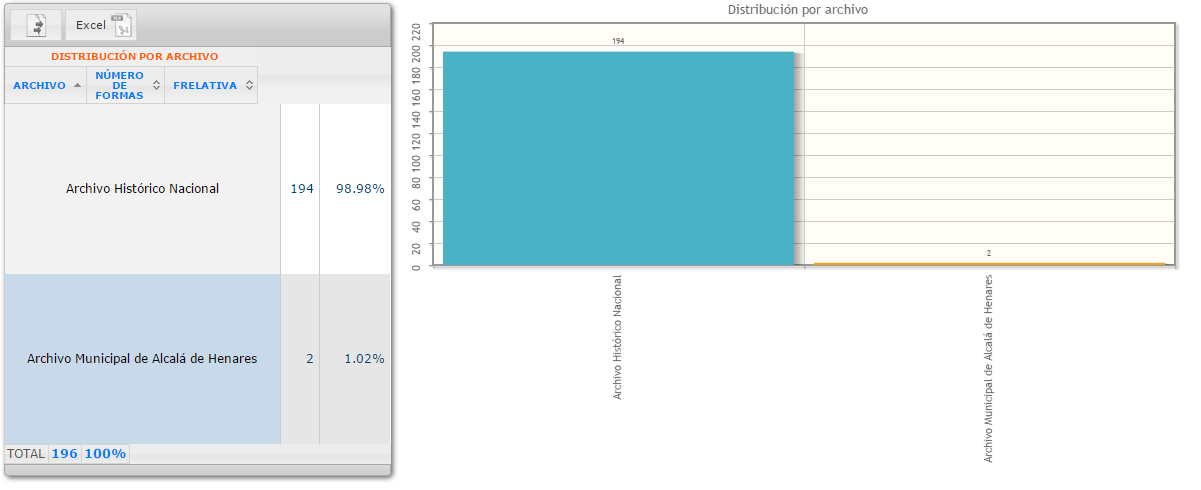
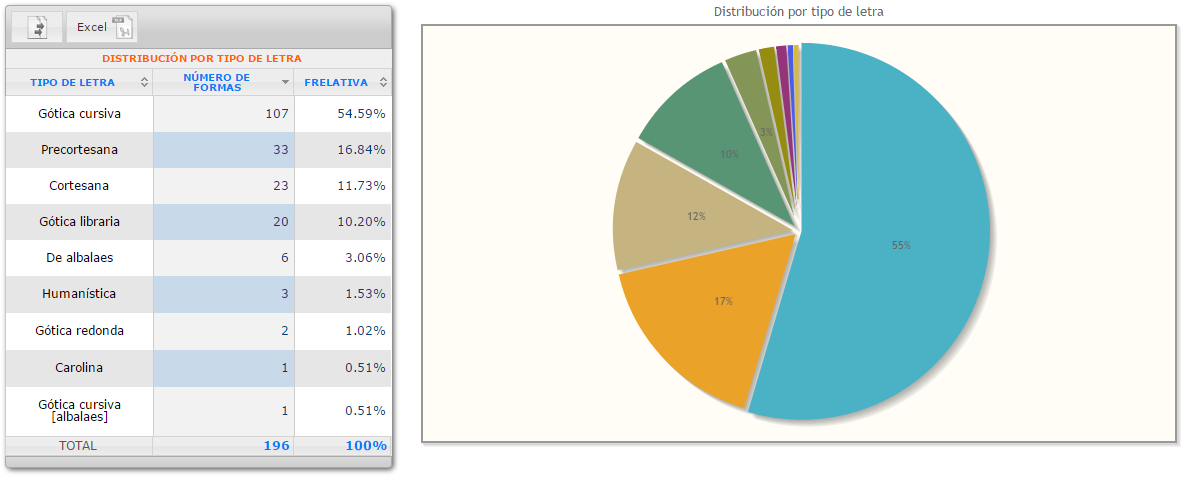
 Codicológico: indica distribución por archivo y tipo de letra.
Codicológico: indica distribución por archivo y tipo de letra.
CODEA es un verdadero Atlas diacrónico dinámico del español. Su forma avanzada de visualización, al proyectar directamente sobre el mapa los resultados de las búsquedas, permite hacerse una idea inmediata del peso del factor geográfico en la variación lingüística histórica en espacio peninsular desde los orígenes a 1900, y no solo para el léxico, sino para cualquier variante gráfica, fonética, morfosintáctica y léxica susceptible de búsqueda en el corpus. Es así posible entender mejor la distribución espacial de las variantes del español y la interrelación entre el factor diatópico y los demás parámetros de la variación lingüística. Pueden ahora buscarse, aparte de distribuciones léxicas, la extensión geográfica de elementos morfosintácticos como [otro/otri/otre/otrie], agora/ahora, *mente/*mientre, el superlativo en [*ísimo], formas verbales en [*rá/*drá], colocaciones [no ... ning*], [no ...alg*] y cualquiera que se le ocurra al usuario, y proyectarse de manera inmediata sobre el mapa de la Península Ibérica.
 Entre los objetivos de la historia de la lengua y la dialectología diacrónicas ha de señalarse la reconstrucción del modo en que se distribuyen arealmente las invariantes lingüísticas.
Entre los objetivos de la historia de la lengua y la dialectología diacrónicas ha de señalarse la reconstrucción del modo en que se distribuyen arealmente las invariantes lingüísticas.
 No resulta fácil, sin embargo, observar esto, a pesar de la sospecha de que la mayor parte de las mismas, tanto fonéticas como morfosintácticas y léxicas, fue sensible a este factor, tanto en su empleo mismo como en la correlación entre frecuencia y variación diatópica.
No resulta fácil, sin embargo, observar esto, a pesar de la sospecha de que la mayor parte de las mismas, tanto fonéticas como morfosintácticas y léxicas, fue sensible a este factor, tanto en su empleo mismo como en la correlación entre frecuencia y variación diatópica.
 Para poder captar esta variación se debe contar con corpus en los que los textos cuenten con una marca geográfica y que reflejen siquiera alguna de las peculiaridades lingüísticas atribuibles a un espacio determinado.
Para poder captar esta variación se debe contar con corpus en los que los textos cuenten con una marca geográfica y que reflejen siquiera alguna de las peculiaridades lingüísticas atribuibles a un espacio determinado.
 Al respecto, las fuentes documentales presentan notables ventajas sobre los textos literarios por reflejar mejor la variación, y por presentar explícita en la mayoría de los casos la data topica o lugar de emisión.
Al respecto, las fuentes documentales presentan notables ventajas sobre los textos literarios por reflejar mejor la variación, y por presentar explícita en la mayoría de los casos la data topica o lugar de emisión.
 Diversos estudios han querido poner en relieve la distribución en diversos niveles de análisis a lo largo del tiempo.
Diversos estudios han querido poner en relieve la distribución en diversos niveles de análisis a lo largo del tiempo.
 Resulta obvia la distribución del léxico, como en el caso de ero, tierra, pedazo, troz, facera, quiñón, etc. para 'parcela de terreno agrícola', pero también en el nivel fonético, debido al lugar preponderante que a este se le ha otorgado en la diferenciación entre dialectos y entre variedades internas dentros de estos.
Por el contrario, no ha sido tan frecuente la investigación en el nivel morfosintáctico, aunque para comprender los cambios lingüísticos en este nivel sea imprescindible la consideración del factor diacrónico.
En esta perspectiva, CODEA+ 2022 se ha dotado de herramientas que permiten visualizar la distribución espacial de las invariantes lingüísticas para cada consulta.
Resulta obvia la distribución del léxico, como en el caso de ero, tierra, pedazo, troz, facera, quiñón, etc. para 'parcela de terreno agrícola', pero también en el nivel fonético, debido al lugar preponderante que a este se le ha otorgado en la diferenciación entre dialectos y entre variedades internas dentros de estos.
Por el contrario, no ha sido tan frecuente la investigación en el nivel morfosintáctico, aunque para comprender los cambios lingüísticos en este nivel sea imprescindible la consideración del factor diacrónico.
En esta perspectiva, CODEA+ 2022 se ha dotado de herramientas que permiten visualizar la distribución espacial de las invariantes lingüísticas para cada consulta.
El CODEA es un corpus realizado con fuentes documentales. ¿Por qué? Porque los estudios de historia lingüística, salvo, por la fuerza de los hechos, para la época de orígenes, no han atendido de manera suficiente a los textos archivísticos, sobre todo a los del s. XVI en adelante. Esta carencia es aun más evidente para el XVIII, siglo, en general, poco trabajado.
En CODEA+ 2022 el concepto de documento se ha entendido en sentido lato, de manera que se identifica con “fuente archivística”. Cualquier pieza relativamente breve, o separable si forma parte de legajos o expedientes amplios, tiene acogida en el corpus.
En particular se ha procurado no dejar fuera escritos elaborados por personas que no han adquirido un dominio completo de la lecto-escritura, las llamadas “manos inhábiles”. Se ha pretendido acoger así un espectro social amplio, que va del documento regio a la nota humilde.
Hasta ahora se incluyen piezas del Archivo Histórico Nacional, Archivo General de Simancas, Municipal de Alcalá de Henares, Municipal de Guadalajara, Municipal de Toledo, Provincial de Guadalajara, Regional de la Comunidad de Madrid, así como de otras instituciones públicas y privadas, incluso de particulares.
CODEA se ha configurado como un corpus primario. Esto quiere decir que, frente a la práctica habitual en otros ámbitos, sobre todo en el anglosajón, que consiste en acoger ediciones previas elaboradas en períodos distantes, incluso en el siglo XIX, y con fines y criterios muy dispares, todos los documentos del CODEA se han seleccionado y transcrito con criterios específicos para este fin. CODEA+ 2022 no acoge ninguna edición ajena al equipo que participa en este proyecto.

Página actualmente en elaboración
En el texto: CODEA+2022 seguido por el número del documento citado, p. ej.
CODEA+2022 1242
En la bibliografía:
Grupo de Investigación Textos para la Historia del Español [GITHE]: CODEA+ 2022 (Corpus de documentos españoles anteriores a 1900) [en línea], doi: https://doi.org/10.37536/CODEA.2015 [consultado en: fecha de la consulta]
 Pedro Sánchez-Prieto Borja se licenció en Filología Hispánica (subsección Lingüística) en la Universidad Complutense de Madrid en 1982, con Premio Extraordinario de Grado de Licenciado. Ha sido Lector de español en la Universidad de Padua (1982-85), y sucesivamente Profesor Ayudante, Titular Interino y Titular de Universidad desde 1993. En 2003 obtuvo la cátedra de Lengua española en la Universidad de Zaragoza, y en 2004 en la de Alcalá. Ha solicitado, y obtenido, cinco quinquenios de docencia y cuatro sexenios de investigación.
Ha sido invitado a participar en programas de Posgrado de la Universidad Autónoma de Madrid, CSIC, Universidad León (Nicaragua), etc. Ha impartido cursos de Doctorado en las universidades de Alcalá, Salamanca, Deusto, Castilla-La Mancha, Complutense, Gotemburgo (Suecia), Universidad Veracruzana (Xalapa, México), Oporto (Portugal), Padua (Italia), etc. Ha dirigido ocho tesis doctorales, y actualmente tiene cuatro en elaboración.
Dirige el “Grupo de Investigación de Textos para la Historia del Español” (GITHE), que ha elaborado el “Corpus de Documentos Españoles Anteriores a 1700” (CODEA). También es coordinador de la Red Internacional CHARTA.
Ha sido Investigador Principal de once proyectos, cuatro de ellos de la convocatoria nacional de I+D+I. Participa como investigador en un proyecto de la UNAM (México). Ha sido investigador responsable de contratos de investigación con la RAE y con la Fundación San Millán de la Cogolla. Ha presentado ponencias y comunicaciones en más de setenta congresos nacionales e internacionales.
Ha participado en comités de evaluación de la investigación de Argentina, México, Portugal y Suiza. Es colaborador del corpus del Nuevo Diccionario Histórico del español de la RAE. Es investigador invitado del Instituto de Estudios Medievales y Renacentistas de la Universidad de Salamanca, Investigador Asociado del Instituto Biblioteca Hispánica del Cilengua, y miembro del Comité Científico del Portal Andrés de Poza (Universidad de Deusto).
Sus publicaciones suman más de ciento sesenta; entre ellas, Cómo editar los textos medievales (Madrid, Arco, 1998), y ha dirigido la edición íntegra de la General estoria de Alfonso X, en 10 vols., y preparado él mismo la edición de las partes Primera, Tercera y Sexta (Biblioteca Castro, 2009). También ha publicado una edición crítica del Lapidario (2014). Es vocal del consejo de redacción de las revistas "Signo. Revista de Historia de la Cultura Escrita", "Revista de Poética Medieval", "Revista de Historia de la Lengua Española", "Diálogo de la lengua". Vocal del Consejo Editorial y del Consejo Científico de la revistas "Biblias Hispánicas" (y miembro del Consejo de Dirección), "Scriptum Digital", “Orillas. Rivista d’Ispanistica”, etc. Dirige la colección Textos para la historia del español (10 vols. publicados).
Es coordinador académico del Convenio entre la Universidad de Alcalá y el Instituto de Cultura Gitana.
En 2012 le fue concedido el Premio a la Transferencia del Conocimiento que otorga el Consejo Social de la Universidad de Alcalá.
Pedro Sánchez-Prieto Borja se licenció en Filología Hispánica (subsección Lingüística) en la Universidad Complutense de Madrid en 1982, con Premio Extraordinario de Grado de Licenciado. Ha sido Lector de español en la Universidad de Padua (1982-85), y sucesivamente Profesor Ayudante, Titular Interino y Titular de Universidad desde 1993. En 2003 obtuvo la cátedra de Lengua española en la Universidad de Zaragoza, y en 2004 en la de Alcalá. Ha solicitado, y obtenido, cinco quinquenios de docencia y cuatro sexenios de investigación.
Ha sido invitado a participar en programas de Posgrado de la Universidad Autónoma de Madrid, CSIC, Universidad León (Nicaragua), etc. Ha impartido cursos de Doctorado en las universidades de Alcalá, Salamanca, Deusto, Castilla-La Mancha, Complutense, Gotemburgo (Suecia), Universidad Veracruzana (Xalapa, México), Oporto (Portugal), Padua (Italia), etc. Ha dirigido ocho tesis doctorales, y actualmente tiene cuatro en elaboración.
Dirige el “Grupo de Investigación de Textos para la Historia del Español” (GITHE), que ha elaborado el “Corpus de Documentos Españoles Anteriores a 1700” (CODEA). También es coordinador de la Red Internacional CHARTA.
Ha sido Investigador Principal de once proyectos, cuatro de ellos de la convocatoria nacional de I+D+I. Participa como investigador en un proyecto de la UNAM (México). Ha sido investigador responsable de contratos de investigación con la RAE y con la Fundación San Millán de la Cogolla. Ha presentado ponencias y comunicaciones en más de setenta congresos nacionales e internacionales.
Ha participado en comités de evaluación de la investigación de Argentina, México, Portugal y Suiza. Es colaborador del corpus del Nuevo Diccionario Histórico del español de la RAE. Es investigador invitado del Instituto de Estudios Medievales y Renacentistas de la Universidad de Salamanca, Investigador Asociado del Instituto Biblioteca Hispánica del Cilengua, y miembro del Comité Científico del Portal Andrés de Poza (Universidad de Deusto).
Sus publicaciones suman más de ciento sesenta; entre ellas, Cómo editar los textos medievales (Madrid, Arco, 1998), y ha dirigido la edición íntegra de la General estoria de Alfonso X, en 10 vols., y preparado él mismo la edición de las partes Primera, Tercera y Sexta (Biblioteca Castro, 2009). También ha publicado una edición crítica del Lapidario (2014). Es vocal del consejo de redacción de las revistas "Signo. Revista de Historia de la Cultura Escrita", "Revista de Poética Medieval", "Revista de Historia de la Lengua Española", "Diálogo de la lengua". Vocal del Consejo Editorial y del Consejo Científico de la revistas "Biblias Hispánicas" (y miembro del Consejo de Dirección), "Scriptum Digital", “Orillas. Rivista d’Ispanistica”, etc. Dirige la colección Textos para la historia del español (10 vols. publicados).
Es coordinador académico del Convenio entre la Universidad de Alcalá y el Instituto de Cultura Gitana.
En 2012 le fue concedido el Premio a la Transferencia del Conocimiento que otorga el Consejo Social de la Universidad de Alcalá.
 Florentino Paredes García es doctor en Filología Hispánica y profesor titular de la Universidad de Alcalá. Su actividad investigadora se desarrolla en los campos de la dialectología, la sociolingüística, la historia de la lengua y la enseñanza del español.
Ha participado en proyectos de investigación como el PRESEEA –para el estudio sociolingüístico del español–, el proyecto panhispánico de Léxico Disponible y diversos proyectos para la edición de documentos hispánicos medievales y de los siglos XVI y XVII. Ha sido el director de los proyectos de investigación INMIGRA2007-CM, sobre la integración sociolingüística de los inmigrantes en Madrid, y PASISMADRID, cuyo objetivo es trazar los patrones sociolingüísticos madrileños y describir los procesos de integración sociolingüística. Es autor de más de cien artículos publicados en revistas nacionales e internacionales.
Entre sus libros relacionados con la didáctica hay manuales, como Proyecto conecta 2. Lengua castellana y literatura. 3º de ESO, Proyecto conecta 2. Lengua castellana y literatura. 4º de ESO (SM, 2009 y 2010) y obras de difusión como la Guía práctica del español correcto (Instituto Cervantes/Espasa, 2008), El libro del español correcto (Instituto Cervantes/Espasa, 2012) o Las 500 dudas más frecuentes del español (Espasa/Instituto Cervantes, 2013). y materiales didácticos para la enseñanza de ELE (En el mundo de los negocios Bratislava, 2002); en dialectología, El habla de La Jara. Los sonidos (Universidad de Alcalá, 2001) y el Diccionario de La Jara (Diputación de Toledo, 2004); en sociolingüística, es coautor de La lengua hablada en Alcalá de Henares. Corpus PRESEEA-ALCALÁ (Universidad de Alcalá, 2002-2007), La lengua hablada en Madrid. Corpus PRESEEA-MADRID (Distrito de Salamanca) (Universidad de Alcalá, 2012-2022), de Estudios sociolingüísticos del español de España y América (Madrid, Arco/Libros, 2006) y de Patrones sociolingüísticos de Madrid (Peter Lang, 2015).
En relación con la edición documental, es autor de Textos para la historia del español III. Archivo municipal de Alcalá de Henares, (Universidad de Alcalá, 2005), y director de Textos para la Historia del español V. Archivo Municipal de Daganzo (Universidad de Alcalá, 2010).
Florentino Paredes García es doctor en Filología Hispánica y profesor titular de la Universidad de Alcalá. Su actividad investigadora se desarrolla en los campos de la dialectología, la sociolingüística, la historia de la lengua y la enseñanza del español.
Ha participado en proyectos de investigación como el PRESEEA –para el estudio sociolingüístico del español–, el proyecto panhispánico de Léxico Disponible y diversos proyectos para la edición de documentos hispánicos medievales y de los siglos XVI y XVII. Ha sido el director de los proyectos de investigación INMIGRA2007-CM, sobre la integración sociolingüística de los inmigrantes en Madrid, y PASISMADRID, cuyo objetivo es trazar los patrones sociolingüísticos madrileños y describir los procesos de integración sociolingüística. Es autor de más de cien artículos publicados en revistas nacionales e internacionales.
Entre sus libros relacionados con la didáctica hay manuales, como Proyecto conecta 2. Lengua castellana y literatura. 3º de ESO, Proyecto conecta 2. Lengua castellana y literatura. 4º de ESO (SM, 2009 y 2010) y obras de difusión como la Guía práctica del español correcto (Instituto Cervantes/Espasa, 2008), El libro del español correcto (Instituto Cervantes/Espasa, 2012) o Las 500 dudas más frecuentes del español (Espasa/Instituto Cervantes, 2013). y materiales didácticos para la enseñanza de ELE (En el mundo de los negocios Bratislava, 2002); en dialectología, El habla de La Jara. Los sonidos (Universidad de Alcalá, 2001) y el Diccionario de La Jara (Diputación de Toledo, 2004); en sociolingüística, es coautor de La lengua hablada en Alcalá de Henares. Corpus PRESEEA-ALCALÁ (Universidad de Alcalá, 2002-2007), La lengua hablada en Madrid. Corpus PRESEEA-MADRID (Distrito de Salamanca) (Universidad de Alcalá, 2012-2022), de Estudios sociolingüísticos del español de España y América (Madrid, Arco/Libros, 2006) y de Patrones sociolingüísticos de Madrid (Peter Lang, 2015).
En relación con la edición documental, es autor de Textos para la historia del español III. Archivo municipal de Alcalá de Henares, (Universidad de Alcalá, 2005), y director de Textos para la Historia del español V. Archivo Municipal de Daganzo (Universidad de Alcalá, 2010).
 Belén Almeida Cabrejas es doctora en Filología Hispánica por la Universidad de Alcalá (2004).
Sus investigaciones se centran en aspectos como la edición crítica de textos medievales (ha editado las partes Segunda y la sección gentil de la Quinta de la General Estoria), el estudio de la historiografía medieval, la prosa alfonsí, la traducción en la Edad Media y, por supuesto, los documentos de archivo. Últimamente se interesa por los rasgos gráficos y lingüísticos de los escriptores menos hábiles y por la evolución de la grafía en los siglos XVIII y XIX, durante el lento proceso de adopción por los hablantes de la grafía recomendada por la RAE.
Ha sido profesora asociada en la Universidad Autónoma de Madrid e investigadora en la Fundación Rafael Lapesa de la Real Academia Española. Actualmente es profesora ayudante doctora en la Universidad de Alcalá. Forma parte del Grupo de investigación de Textos para la historia del español (GITHE), y ha participado en diversos proyectos de investigación bajo la dirección de Pedro Sánchez-Prieto Borja, su director de tesis, de Inés Fernández-Ordóñez y de Georges Martin.
Belén Almeida Cabrejas es doctora en Filología Hispánica por la Universidad de Alcalá (2004).
Sus investigaciones se centran en aspectos como la edición crítica de textos medievales (ha editado las partes Segunda y la sección gentil de la Quinta de la General Estoria), el estudio de la historiografía medieval, la prosa alfonsí, la traducción en la Edad Media y, por supuesto, los documentos de archivo. Últimamente se interesa por los rasgos gráficos y lingüísticos de los escriptores menos hábiles y por la evolución de la grafía en los siglos XVIII y XIX, durante el lento proceso de adopción por los hablantes de la grafía recomendada por la RAE.
Ha sido profesora asociada en la Universidad Autónoma de Madrid e investigadora en la Fundación Rafael Lapesa de la Real Academia Española. Actualmente es profesora ayudante doctora en la Universidad de Alcalá. Forma parte del Grupo de investigación de Textos para la historia del español (GITHE), y ha participado en diversos proyectos de investigación bajo la dirección de Pedro Sánchez-Prieto Borja, su director de tesis, de Inés Fernández-Ordóñez y de Georges Martin.
 María Agujetas Ortiz es graduada en Estudios Hispánicos en la Universidad de Alcalá, donde también cursó el Máster en Documentación, Archivos y Bibliotecas.
Es miembro del Grupo de Investigación de Textos para la Historia del Español (GITHE), en el que ha colaborado en el proyecto CODEA+2020 como personal técnico de apoyo (PTA).
Entre su publicaciones, cabe destacar las siguientes: M. Agujetas Ortiz & P. Sánchez-Prieto Borja (2022), “Nuevas vías para la recuperación de información en corpus históricos: clasificación del vocabulario”, Scriptum digital,11, pp. 5-54. M. Agujetas Ortiz (2022), Textos para la Historia del Español XV. Real biblioteca del monasterio de San Lorenzo de El Escorial, Alcalá de Henares, Editorial Universidad de Alcalá. M. Agujetas Ortiz, P. Sánchez-Prieto Borja & H. Ueda (2022), Inventario léxico de Castilla la Nueva. Corpus CODEA [en línea]. M. Agujetas Ortiz & Sánchez-Prieto Borja (2020), Lengua de la administración y habla popular. Edición y estudio del Libro de villazgo de Torrejón del Rey (1579), Alcalá de Henares, Editorial Universidad de Alcalá.
María Agujetas Ortiz es graduada en Estudios Hispánicos en la Universidad de Alcalá, donde también cursó el Máster en Documentación, Archivos y Bibliotecas.
Es miembro del Grupo de Investigación de Textos para la Historia del Español (GITHE), en el que ha colaborado en el proyecto CODEA+2020 como personal técnico de apoyo (PTA).
Entre su publicaciones, cabe destacar las siguientes: M. Agujetas Ortiz & P. Sánchez-Prieto Borja (2022), “Nuevas vías para la recuperación de información en corpus históricos: clasificación del vocabulario”, Scriptum digital,11, pp. 5-54. M. Agujetas Ortiz (2022), Textos para la Historia del Español XV. Real biblioteca del monasterio de San Lorenzo de El Escorial, Alcalá de Henares, Editorial Universidad de Alcalá. M. Agujetas Ortiz, P. Sánchez-Prieto Borja & H. Ueda (2022), Inventario léxico de Castilla la Nueva. Corpus CODEA [en línea]. M. Agujetas Ortiz & Sánchez-Prieto Borja (2020), Lengua de la administración y habla popular. Edición y estudio del Libro de villazgo de Torrejón del Rey (1579), Alcalá de Henares, Editorial Universidad de Alcalá.
 Rocío Díaz Moreno es doctora en Filología Hispánica por la Universidad de Alcalá (2004).
Sus líneas de investigación se han centrado en la edición y estudio de textos medievales y, sobre todo, de los siglos XVI y XVII. En este momento trabaja en la edición y análisis de documentación de manos inhábiles de los siglos XVIII y XIX.
En la actualidad es profesora asociada en el área de Lengua Española en el Departamento de Filología, Comunicación y Documentación de la Universidad de Alcalá. Pertenece al Grupo de Investigación de Textos para la Historia del Español (GITHE). Ha participado en diversos proyectos de investigación sobre el tema desde 1996 y en proyectos de estudio sociolingüístico del español como PRESEEA e INMIGRA2007-CM (estudio sociolingüístico de inmigrantes en la Comunidad de Madrid).
Rocío Díaz Moreno es doctora en Filología Hispánica por la Universidad de Alcalá (2004).
Sus líneas de investigación se han centrado en la edición y estudio de textos medievales y, sobre todo, de los siglos XVI y XVII. En este momento trabaja en la edición y análisis de documentación de manos inhábiles de los siglos XVIII y XIX.
En la actualidad es profesora asociada en el área de Lengua Española en el Departamento de Filología, Comunicación y Documentación de la Universidad de Alcalá. Pertenece al Grupo de Investigación de Textos para la Historia del Español (GITHE). Ha participado en diversos proyectos de investigación sobre el tema desde 1996 y en proyectos de estudio sociolingüístico del español como PRESEEA e INMIGRA2007-CM (estudio sociolingüístico de inmigrantes en la Comunidad de Madrid).
 Mª del Carmen Fernández López es doctora en Filología Hispánica por la Universidad de Alcalá (1997) y profesora Titular de Universidad de Lengua Española en el Departamento de Filología, Comunicación y Documentación de la Universidad de Alcalá.
Sus investigaciones se han centrado en la edición crítica de textos medievales y de los siglos XVI y XVII; ha editado el Libro de Isaías; contenido en la Tercera Parte de la General estoria de Alfonso X (2010) y El León de España de Pedro de la Vecilla Castellanos (Salamanca, 1586). Pertenece al Grupo de Investigación de Textos para la Historia del Español (GITHE); ha participado en diversos proyectos de investigación sobre el tema desde 1992 bajo la dirección de Carlos Alvar y Pedro Sánchez-Prieto, y publicado en la colección Textos para la historia del español (vols. I y II).
Mª del Carmen Fernández López es doctora en Filología Hispánica por la Universidad de Alcalá (1997) y profesora Titular de Universidad de Lengua Española en el Departamento de Filología, Comunicación y Documentación de la Universidad de Alcalá.
Sus investigaciones se han centrado en la edición crítica de textos medievales y de los siglos XVI y XVII; ha editado el Libro de Isaías; contenido en la Tercera Parte de la General estoria de Alfonso X (2010) y El León de España de Pedro de la Vecilla Castellanos (Salamanca, 1586). Pertenece al Grupo de Investigación de Textos para la Historia del Español (GITHE); ha participado en diversos proyectos de investigación sobre el tema desde 1992 bajo la dirección de Carlos Alvar y Pedro Sánchez-Prieto, y publicado en la colección Textos para la historia del español (vols. I y II).
 Hiroto Ueda trabaja en la Universidad de Tokio en los departamentos de Lengua Española y de Estudios Interdisciplinarios de Ciencias Informáticas.
Sus campos de investigación son: historia de grafías españolas, con atención preferente al castellano medieval; variación léxica del español moderno en sus aspectos geográficos, en 20 países hispanohablantes; cuestiones de gramática descriptiva del español moderno; fonética contrastiva del español y del japonés con aplicaciones didácticas; utilización de medios informáticos en la enseñanza del español; estadística lingüística con los últimos desarrollos de métodos probabilísticos y análisis multivariacionales.
Por otra parte, se dedica a elaborar programas informáticos de tratamientos digitales de textos, audios, vídeos y mapas en Excel-VBA. Últimamente ha construido dos sitios web con programas en PHP para análisis general de datos lingüísticos y numéricos, donde se encuentran los datos ofrecidos por el Proyecto CODEA +2022.
Hiroto Ueda trabaja en la Universidad de Tokio en los departamentos de Lengua Española y de Estudios Interdisciplinarios de Ciencias Informáticas.
Sus campos de investigación son: historia de grafías españolas, con atención preferente al castellano medieval; variación léxica del español moderno en sus aspectos geográficos, en 20 países hispanohablantes; cuestiones de gramática descriptiva del español moderno; fonética contrastiva del español y del japonés con aplicaciones didácticas; utilización de medios informáticos en la enseñanza del español; estadística lingüística con los últimos desarrollos de métodos probabilísticos y análisis multivariacionales.
Por otra parte, se dedica a elaborar programas informáticos de tratamientos digitales de textos, audios, vídeos y mapas en Excel-VBA. Últimamente ha construido dos sitios web con programas en PHP para análisis general de datos lingüísticos y numéricos, donde se encuentran los datos ofrecidos por el Proyecto CODEA +2022.
 Delfina Vázquez Balonga es licenciada en Filología Hispánica por la Universidad de Alcalá (2009). Pertenece al Grupo de Investigación de Textos para la Historia del Español (GITHE) de la UAH desde 2010.
Ha finalizado su tesis doctoral sobre documentación de Madrid y Toledo en los Siglos de Oro, bajo la dirección de Pedro Sánchez-Prieto Borja. Ha publicado el libro Textos para la Historia del Español VIII. Archivo Municipal de Arganda del Rey (Universidad de Alcalá). Sus líneas de investigación principales son el léxico y la onomástica de documentos archivísticos españoles de los siglos XVI, XVII y XVIII.
Delfina Vázquez Balonga es licenciada en Filología Hispánica por la Universidad de Alcalá (2009). Pertenece al Grupo de Investigación de Textos para la Historia del Español (GITHE) de la UAH desde 2010.
Ha finalizado su tesis doctoral sobre documentación de Madrid y Toledo en los Siglos de Oro, bajo la dirección de Pedro Sánchez-Prieto Borja. Ha publicado el libro Textos para la Historia del Español VIII. Archivo Municipal de Arganda del Rey (Universidad de Alcalá). Sus líneas de investigación principales son el léxico y la onomástica de documentos archivísticos españoles de los siglos XVI, XVII y XVIII.
 Sara Gómez Seibane es doctora en Filología Hispánica por la Universidad de Deusto. Ha sido profesora de Lengua española en la Facultad de Letras de la Universidad de Castilla-La Mancha (2007-2014) y desde el curso 2014/15 lo es en la Facultad de Letras y de Educación de la Universidad de La Rioja.
Su actividad investigadora se centra en la morfosintaxis del español en un amplio marco cronológico y con especial atención a las situaciones de contacto lingüístico del español con el gallego y el vasco. Sobre esta última cuestión ha publicado “Algunos fenómenos sintácticos del español en Galicia (1767-1806)”, AEF, 35 (2012), "Contacto de lenguas y orden de palabras: OV/VO en el español del País Vasco", LEA, 34/1 (2012) y ha coeditado con B. Camus El castellano del País Vasco (Bilbao, UPV, 2012) y con C. Sinner Estudios sobre tiempo y espacio en el español norteño (San Millán de la Cogolla, Cilengua, 2012). Asimismo es autora de Los pronombres átonos (le, la, lo) en español y Los pronombres átonos (le, la, lo) en español: aproximación histórica (Madrid, Arco Libros, 2012 y 2013).
En cuanto a su labor en documentación de archivo, integrada desde 2006 en la red internacional CHARTA, edita textos de los siglos XVII, XVIII y XIX en castellano en áreas de contacto con la lengua vasca y la gallega, como en los volúmenes Bilbao en sus documentos (1544-1694), El castellano de Bilbao en el siglo XVIII: Materiales para su estudio (Bilbao, Universidad de Deusto, 2007), así como correspondencia privada (Moenia 17: 367-420 y en la obra colectiva Una muestra documental del castellano norteño del siglo XIX, Lugo, Axac, 2013).
Sara Gómez Seibane es doctora en Filología Hispánica por la Universidad de Deusto. Ha sido profesora de Lengua española en la Facultad de Letras de la Universidad de Castilla-La Mancha (2007-2014) y desde el curso 2014/15 lo es en la Facultad de Letras y de Educación de la Universidad de La Rioja.
Su actividad investigadora se centra en la morfosintaxis del español en un amplio marco cronológico y con especial atención a las situaciones de contacto lingüístico del español con el gallego y el vasco. Sobre esta última cuestión ha publicado “Algunos fenómenos sintácticos del español en Galicia (1767-1806)”, AEF, 35 (2012), "Contacto de lenguas y orden de palabras: OV/VO en el español del País Vasco", LEA, 34/1 (2012) y ha coeditado con B. Camus El castellano del País Vasco (Bilbao, UPV, 2012) y con C. Sinner Estudios sobre tiempo y espacio en el español norteño (San Millán de la Cogolla, Cilengua, 2012). Asimismo es autora de Los pronombres átonos (le, la, lo) en español y Los pronombres átonos (le, la, lo) en español: aproximación histórica (Madrid, Arco Libros, 2012 y 2013).
En cuanto a su labor en documentación de archivo, integrada desde 2006 en la red internacional CHARTA, edita textos de los siglos XVII, XVIII y XIX en castellano en áreas de contacto con la lengua vasca y la gallega, como en los volúmenes Bilbao en sus documentos (1544-1694), El castellano de Bilbao en el siglo XVIII: Materiales para su estudio (Bilbao, Universidad de Deusto, 2007), así como correspondencia privada (Moenia 17: 367-420 y en la obra colectiva Una muestra documental del castellano norteño del siglo XIX, Lugo, Axac, 2013).
 Marta Torres Martínez es doctora en Filología Hispánica por la Universidad de Jaén (2009).
Sus investigaciones se centran en aspectos como el estudio de la formación de palabras desde el punto de vista de la historiografía lingüística y de la lexicografía, así como en el análisis del léxico histórico en fuentes documentales y en diccionarios del español. Actualmente, es profesora contratada doctora en el Departamento de Filología Española de la Universidad de Jaén e integrante del Grupo de Investigación "Seminario de Lexicografía Hispánica". Ha participado en diversos proyectos de investigación, entre ellos, el “Corpus de documentos españoles anteriores a 1800: CODEA+2015”, dirigido por el doctor Pedro Sánchez-Prieto Borja.
Marta Torres Martínez es doctora en Filología Hispánica por la Universidad de Jaén (2009).
Sus investigaciones se centran en aspectos como el estudio de la formación de palabras desde el punto de vista de la historiografía lingüística y de la lexicografía, así como en el análisis del léxico histórico en fuentes documentales y en diccionarios del español. Actualmente, es profesora contratada doctora en el Departamento de Filología Española de la Universidad de Jaén e integrante del Grupo de Investigación "Seminario de Lexicografía Hispánica". Ha participado en diversos proyectos de investigación, entre ellos, el “Corpus de documentos españoles anteriores a 1800: CODEA+2015”, dirigido por el doctor Pedro Sánchez-Prieto Borja.
 Diego Sánchez Sierra se graduó en 2013 en Estudios Hispánicos por la Universidad de Alcalá, donde también ha cursado el Máster en Formación de Profesores de Español (Especialidad en Enseñanza de Español como Lengua Extranjera). Forma parte del (GITHE) desde 2014.
Actualmente prepara su tesis doctoral sobre el léxico en documentos extremeños de los siglos XVI y XVII bajo la dirección del catedrático Pedro Sánchez-Prieto Borja. Sus líneas de investigación son el castellano de los Siglos de Oro, la edición de fuentes documentales y la Historia del léxico.
Diego Sánchez Sierra se graduó en 2013 en Estudios Hispánicos por la Universidad de Alcalá, donde también ha cursado el Máster en Formación de Profesores de Español (Especialidad en Enseñanza de Español como Lengua Extranjera). Forma parte del (GITHE) desde 2014.
Actualmente prepara su tesis doctoral sobre el léxico en documentos extremeños de los siglos XVI y XVII bajo la dirección del catedrático Pedro Sánchez-Prieto Borja. Sus líneas de investigación son el castellano de los Siglos de Oro, la edición de fuentes documentales y la Historia del léxico.
 Alba Gómez González es graduada en Estudios Hispánicos por la Universidad de Alcalá (2013), donde amplía su formación con posgrados oficiales en el ámbito de la enseñanza del español como lengua materna y como lengua extranjera.
Diseñadora de material didáctico, es coautora del libro Locuciones y refranes para dar y tomar. El libro para aprender más de 120 locuciones y refranes del español. Niveles B2 y C1 (2014), editado por el Servicio de Publicaciones de la Universidad de Alcalá. Es formadora de profesores de español en un curso propio de esta universidad y cuenta con experiencia en la docencia del español para extranjeros en varios centros acreditados por el Instituto Cervantes, labor que en la actualidad compagina con la investigación en el proyecto CODEA+2015.
Alba Gómez González es graduada en Estudios Hispánicos por la Universidad de Alcalá (2013), donde amplía su formación con posgrados oficiales en el ámbito de la enseñanza del español como lengua materna y como lengua extranjera.
Diseñadora de material didáctico, es coautora del libro Locuciones y refranes para dar y tomar. El libro para aprender más de 120 locuciones y refranes del español. Niveles B2 y C1 (2014), editado por el Servicio de Publicaciones de la Universidad de Alcalá. Es formadora de profesores de español en un curso propio de esta universidad y cuenta con experiencia en la docencia del español para extranjeros en varios centros acreditados por el Instituto Cervantes, labor que en la actualidad compagina con la investigación en el proyecto CODEA+2015.
 Marina Serrano Marín es licenciada en Filología Hispánica por la Universidad de Alcalá (2011). Continuó sus estudios universitarios con la realización del Máster en Formación del Profesorado de la UAH y el Máster en Fonética y Fonología del CSIC-UIMP. Es miembro del grupo (GITHE) desde 2014.
Actualmente prepara su tesis en la UAH sobre variación diacrónica en morfología verbal del español bajo la dirección de Pedro Sánchez-Prieto Borja.
Marina Serrano Marín es licenciada en Filología Hispánica por la Universidad de Alcalá (2011). Continuó sus estudios universitarios con la realización del Máster en Formación del Profesorado de la UAH y el Máster en Fonética y Fonología del CSIC-UIMP. Es miembro del grupo (GITHE) desde 2014.
Actualmente prepara su tesis en la UAH sobre variación diacrónica en morfología verbal del español bajo la dirección de Pedro Sánchez-Prieto Borja.
 Ricardo Pichel es doctor en Filología Gallega (2013) y Licenciado en Filología Hispánica (2006) por la Universidade de Santiago de Compostela, de la que continúa como investigador colaborador externo del Instituto da Lingua Galega. Trabajó en la Universidad Complutense de Madrid (2011-14), de la que continúa como colaborador honorífico desde 2014.
En etapa posdoctoral ha sido beneficiario de varios contratos de investigación en la Universidade de Santiago de Compostela (2014-16), Universidade do Porto (FCT 2015) y en la Universidad de Alcalá (Juan de la Cierva-Formación, 2016-18; Juan de la Cierva-Incorporación, 2018-19, Atracción de Talento de la Comunidad de Madrid, 2019-23). Ha realizado varias estancias de investigación en centros europeos y de EE. UU.: Institut de Recherche et d'Histoire des Textes (Paris, 2010), Universidade do Porto (2014), University of Birmingham (2015-16), King's College London (2016), Hispanic Society of America (NY, 2016), University of California-Santa Barbara (2017) y Georgetown University (Washington, 2017).
Sus líneas principales de investigación son el estudio de las fuentes archivísticas (hispánicas y novohispanas) y de la prosa literaria, historiográfica y jurídica medieval. Actualmente es IP de dos proyectos de investigación dentro del grupo GITHE: “HERES. Patrimonio textual ibérico y novohispano. Recuperación y memoria” 2019-2024 (CM, Ref. 2018-T1/HUM-10230) y “CHARTA 3.0: de la edición digital a la web semántica” 2020-2021 (CM/JIN/2019-008).
Ricardo Pichel es doctor en Filología Gallega (2013) y Licenciado en Filología Hispánica (2006) por la Universidade de Santiago de Compostela, de la que continúa como investigador colaborador externo del Instituto da Lingua Galega. Trabajó en la Universidad Complutense de Madrid (2011-14), de la que continúa como colaborador honorífico desde 2014.
En etapa posdoctoral ha sido beneficiario de varios contratos de investigación en la Universidade de Santiago de Compostela (2014-16), Universidade do Porto (FCT 2015) y en la Universidad de Alcalá (Juan de la Cierva-Formación, 2016-18; Juan de la Cierva-Incorporación, 2018-19, Atracción de Talento de la Comunidad de Madrid, 2019-23). Ha realizado varias estancias de investigación en centros europeos y de EE. UU.: Institut de Recherche et d'Histoire des Textes (Paris, 2010), Universidade do Porto (2014), University of Birmingham (2015-16), King's College London (2016), Hispanic Society of America (NY, 2016), University of California-Santa Barbara (2017) y Georgetown University (Washington, 2017).
Sus líneas principales de investigación son el estudio de las fuentes archivísticas (hispánicas y novohispanas) y de la prosa literaria, historiográfica y jurídica medieval. Actualmente es IP de dos proyectos de investigación dentro del grupo GITHE: “HERES. Patrimonio textual ibérico y novohispano. Recuperación y memoria” 2019-2024 (CM, Ref. 2018-T1/HUM-10230) y “CHARTA 3.0: de la edición digital a la web semántica” 2020-2021 (CM/JIN/2019-008).
 Francisco Javier Pueyo Mena es científico titular en el CCHS del CSIC. Su investigación se centra en la edición y estudio de los textos bíblicos hispánicos, tanto de las versiones castellanas medievales como de las traducciones sefardíes (aljamiadas o no), producidas fuera de España después de la expulsión de 1492.
Dentro de sus publicaciones cabe destacar la edición de dos de los romanceamientos bíblicos medievales (RAH y BNE). En la actualidad participa en la edición crítica y anotada de la traducción y comentario de la Biblia de Arragel, junto a Luis Girón-Negrón (Harvard University), Ángel Sáez-Badillos (Universidad Complutense) y Andrés Enrique-Arias (Universidad de las Islas Baleares).
Francisco Javier Pueyo Mena es científico titular en el CCHS del CSIC. Su investigación se centra en la edición y estudio de los textos bíblicos hispánicos, tanto de las versiones castellanas medievales como de las traducciones sefardíes (aljamiadas o no), producidas fuera de España después de la expulsión de 1492.
Dentro de sus publicaciones cabe destacar la edición de dos de los romanceamientos bíblicos medievales (RAH y BNE). En la actualidad participa en la edición crítica y anotada de la traducción y comentario de la Biblia de Arragel, junto a Luis Girón-Negrón (Harvard University), Ángel Sáez-Badillos (Universidad Complutense) y Andrés Enrique-Arias (Universidad de las Islas Baleares).
Francisco Javier Pueyo es experto en la creación y aprovechamiento filológico de recursos computacionales en el área de las Humanidades Digitales y en el campo del procesamiento del lenguaje natural (PLN). Puede destacarse su participación en la dirección técnica y el desarrollo digital de proyectos como Biblia Medieval, Corpus Mallorca, el Corpus Histórico del Judoespañol o el Diccionario Histórico del Judeoespañol.
Se ha responsabilizado también del desarrollo e implantación de los corpus documentales CHARTA y CODEA y en la actualidad trabaja en la normalización, lematización, etiquetación gramatical y arquitectura tanto del corpus Biblia Medieval, como del amplio corpus textual del Hispanic Seminary of Medieval Studies (junto a Francisco J. Gago-Jover, HSMS/Holly Cross).
 José Luis Ramírez Luengo es doctor en Filología Hispánica por la Universidad de Deusto (España), y actualmente desarrolla su labor docente e investigadora en la Universidad Autónoma de Querétaro (México). Ha investigado e impartido docencia, además, en la Universidad de Jaén y en la Universidad de Alcalá (España), así como invitado en diferentes instituciones de enseñanza superior de Europa e Iberoamérica.
José Luis Ramírez Luengo es doctor en Filología Hispánica por la Universidad de Deusto (España), y actualmente desarrolla su labor docente e investigadora en la Universidad Autónoma de Querétaro (México). Ha investigado e impartido docencia, además, en la Universidad de Jaén y en la Universidad de Alcalá (España), así como invitado en diferentes instituciones de enseñanza superior de Europa e Iberoamérica.
Su ámbito de investigación fundamental lo constituye la historia de la lengua española en la época moderna, tanto en España como en América, así como el contacto lingüístico del español con el portugués desde un punto de vista histórico y la configuración de la ortografía moderna; sobre tales temas ha publicado más de un centenar de trabajos y reseñas en revistas científicas, entre los que destacan su Breve Historia del Español de América (Madrid: Arco Libros, 2007), La lengua que hablaban los próceres. El español de América en la época de las Independencias (Buenos Aires: Voces del Sur, 2011) o Una descripción del español de mediados del siglo XVIII. Edición y estudio de las cartas de M. Martierena del Barranco (1757-1763) (Lugo: Axac, 2013).
Para una caracterización registral y sociolingüística de los documentos, estos se han clasificado con respecto de tres parámetros
|
Ámbito de emisión, en el que fue elaborada la pieza
|
cancilleresco, judicial, municipal, eclesiástico, privado
Este criterio puede tener el interés añadido de reflejar tal vez una escala registral de más formal a menos en el orden señalado.
|
|
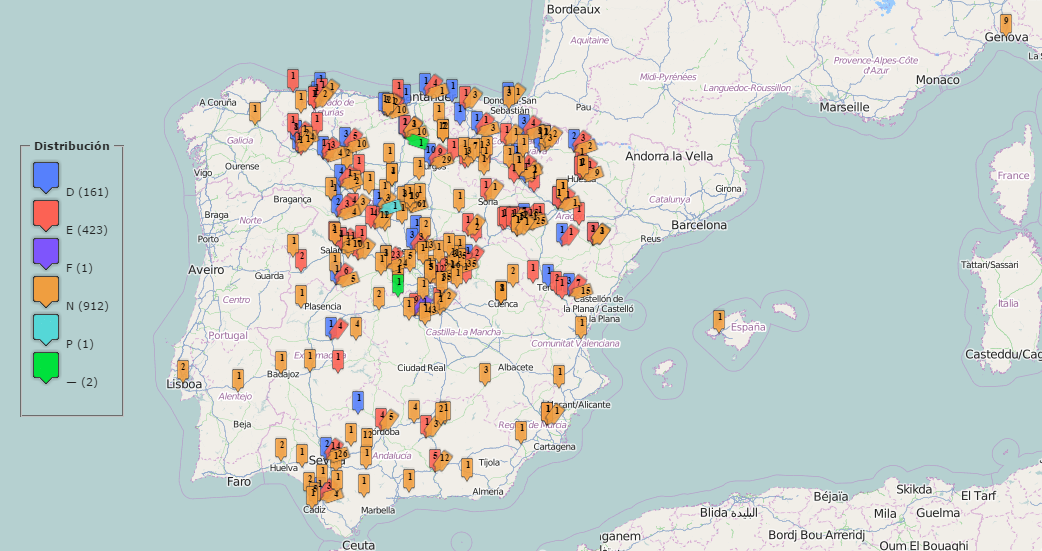
Tipología documental CHARTA
|
Textos legislativos
Cartas de compraventa y contratos
Actas y declaraciones
Cartas privadas
Testamentos e inventarios
Informes y relaciones
Estatutos
Certificaciones
Notas y breves
Otros
|
|
Tipología diplomática, en sentido tradicional
|
privilegios rodados, cartas plomadas, mandatos, compraventas, donaciones, permutas, actas, sentencias, testimonios, cartas privadas, inventarios, testamentos, codicilos, deslindes, informes, estatutos, certificaciones, cartas de poder, notas de abandono, etc.
|
CODEA+ 2022 se presenta completamente lematizado y categorizado gramaticalmente de manera interactiva. Es posible así hacer búsquedas por formas y por lemas. Esto facilita también la búsqueda de colocaciones.
El uso de la lematización y de la categorización en las consultas es muy similar a la busqueda por formas y se integra en el mismo buscador que estas. De esta manera se pueden realizar consultas complejas que
combinen formas, lemas y etiquetas en cualquier posición de la cadena de búsqueda. Para diferenciar los lemas y las etiquetas de las formas, se usarán corchetes [] para envolver los lemas y llaves {} para envolver
las etiquetas. Por lo tanto podemos buscar la forma "casas" o el lema [casa] o la etiqueta gramatical {NC*}. Al igual que las formas, los lemas y las etiquetas admiten comodines (siempre dentro de los corchetes o llaves),
por lo que podemos buscar todos los lemas que comiencen por "ca" escribiendo [ca*] (CASA, CARTA, CAUSA, CADA). Igualmente es posible restringir los lemas por etiqueta: [ca*]+{NC*} (lemas que comiencen por ca-, pero solo los
sustantivos) o buscar lemas y etiquetas alternativos en cualquier posición del buscador: [casa]/[carta] o {NC*}/{A*} (nombre o adjetivo). El siguiente ejemplo, muestra una búsqueda compleja combinando todos estos elementos:
[SER]/[ESTAR] {V*}+[O*] {SP*}
Es decir, cualquier forma de los verbos SER o ESTAR seguida de cualquier verbo cuyo lema comience por "O" y, a su vez, seguido de una preposición: "sean osados de", "son obligados a", "estamos obligadas a", etc.
Puede usarse también el botón de ayuda para la generación de consultas pinchando en el icono: 
Aunque debe tenerse en cuenta que por el momento solo se pone a disposición del investigador la categoría principal de las etiquetas gramaticales, es decir, {NP*} (nombre propio), {NC*} (nombre común),
{V*} (verbo), {A*} (adjetivo), {DA*} (artículo), etc. Se espera en un futuro cercano dar acceso a otros niveles gramaticales como género, número, modo y tiempo verbales, persona, etc.
El corpus incluye una lista de palabras clave de todos los documentos (en un número máximo de diez por cada uno). Se establece así un verdadero mapa semántico y referencial del corpus y una verdadera web semántica.
-
ALMEIDA, B., P. SÁNCHEZ-PRIETO BORJA, D. VÁZQUEZ BALONGA. “Aproximación a los usos pronominales toledanos” (En prensa). Actas del IX Congreso Internacional de Historia de la Lengua Española. Cádiz, 10-14 de septiembre de 2012.
-
ALMEIDA, B. (En prensa). “Evolución de las fórmulas en las cartas de venta del CODEA (I)”, en Actas del IX Congreso Internacional de Historia de la Lengua Española. Cádiz, 10-14 de septiembre de 2012.
-
BONILLA, H. (2015): Estudio paleográfico, gráfico-fonético y morfosintáctico de documentos medievales de Molina de Aragón. Trabajo Fin de Grado. Estudios Hispánicos. Universidad de Alcalá.
-
CRUZ GOMES, V. (2013). Caracterización registral y sociolingüística de las cartas privadas incluidas en el CODEA en los siglos XVI y XVII. Trabajo final de máster presentado en la Universidad Autónoma de Madrid.
-
CUADROS MUÑOZ, R. (2011). “Sepan quantos este privilegio vieren: observaciones sobre el paradigma demostrativo de primera persona en la documentación diplomática medieval”. Cahiers d´Études Hispaniques Médiévales, 34, 203-233.
-
DEL BARRIO, F. (En prensa). “Factores estilísticos en la evolución de los posesivos en español antiguo”.
-
DEL BARRIO, F. “De tener a tener. La difusión de tener como verbo de posesión en la historia del español: Contextos y focos”.
-
DEL BARRIO, F. (en prensa). “La distribución de las variantes -mente, -miente y –mientre en el CODEA (1221-1420)”.
-
DÍAZ MORENO, R., R. MARTÍNEZ SÁNCHEZ, J. L. RAMÍREZ LUENGO y P. SÁNCHEZ-PRIETO BORJA (En prensa). “Hacia una cronología evolutiva del español”, Actas del IX Congreso Internacional de Historia de la Lengua Española. Cádiz, 10-14 de septiembre de 2012.
-
DÍAZ, R., R. MARTÍNEZ SÁNCHEZ, P. SÁNCHEZ – PRIETO BORJA y D. VÁZQUEZ BALONGA (2011). “El CODEA, un corpus primario de fuentes documentales del español peninsular”. En: Actas del XVI Congreso Internacional de ALFAL, 2629-2638.
-
DÍEZ DEL CORRAL, E. (en prensa), “La problemática de las tradiciones textuales en el estudio lingüístico del documento indiano”, Actas del II Congreso Internacional Tradición e Innovación: nuevas perspectivas para la edición y el estudio de documentos antiguos (Neuchâtel, septiembre 2011).
-
KAWASAKI, Y. (2014). “Datación crono-geográfica de documentos medievales españoles”. Scriptum Digital, 3, 29-63.
-
MIGUEL FRANCO, R. y P. SÁNCHEZ-PRIETO BORJA (En prensa). “CODEA: a "primary" corpus of Spanish Documents”, Variants.
-
PAREDES, F. (en prensa), “Factores condicionantes de la variación otro/otri/otre/otrie en español medieval”.
-
PAREDES GARCÍA, P. (2005). Textos para la historia del español. III Archivo Municipal de Alcalá de Henares. División histórica, Alcalá de Henares, Universidad de Alcalá.
-
PLANCHUELO FERNÁNDEZ, C. (2014). Evolución de los marcadores discursivos con tanto. TFG, Estudios Hispánicos. Universidad de Alcalá.
-
SÁNCHEZ-PRIETO BORJA, P. (2011): “Ensayo de geografía lingüística histórica: términos para 'parcela de terreno agrícola' en las fuentes documentales de la Edad Media”, en GÓMEZ SEIBANE, Sara y RAMÍREZ LUENGO, José Luis (eds.) (2011): Maestra en mucho. Estudios filológicos en Homenaje a Carmen Isasi Martínez. Buenos Aires: Ediciones Voces del Sur, pp. 271-302.
-
SÁNCHEZ-PRIETO BORJA, P. (2012). “Desarrollo y explotación del «Corpus de Documentos Españoles Anteriores a 1700(CODEA)” , Scriptum Digital, I, pp. 5-35 .
-
SÁNCHEZ-PRIETO BORJA, P. (2012). “La preposición a con valor ‘lugar en donde’ en castellano antiguo”, Les nouvelles ambitions de la linguistique diachronique. Travaux de la section “Linguistique diachronique”. Actes du XXIIe Congrès International de Linguistique et de Philologie Romanes, Bruxelles, 23-29 juillet 1998, publiés par Annick Englebert, Michel Pierrard, Laurence Rosier et Dan Van Raemdonck, vol. II, Tubinga, Max Niemeyer Verlag, 2000, págs. 393-406.
-
SÁNCHEZ-PRIETO BORJA, P. (2002): “Sobre una supuesta evolución circular en español: CAUSA> cabsa > causa (con reflexiones sobre el concepto de ultracorrección)” [Documentos del CODEA], en SARALEGUI, Carmen y CASADO, Manuel (2002): Pulchre, bene recte. Estudios en homenaje al prof. Fernando González Ollé. Pamplona: EUNSA, pp. 1287-1310.
-
SÁNCHEZ-PRIETO BORJA, P. y A. FLORES (2005). Textos para la Historia del español, IV. Archivo Regional de la Comunidad de Madrid. Alcalá de Henares, Universidad de Alcalá.
-
SÁNCHEZ-PRIETO BORJA, P. y M. J. TORRENS ÁLVAREZ. (2008): “Las tradiciones de escritura del País Vasco comparadas con las de las regiones limítrofes”, en Oihenart, nº 23, pp. 481-502.
-
SIMÓN PARRA, M. (2011). “Aspectos morfológicos de los nombres de pila y de los apellidos medievales del Corpus de Documentos Españoles anteriores a 1700 (CODEA)”. En: Moenia, 17, 321-332.
-
SIMÓN PARRA, M. (2009): El nombre de persona en la documentación castellana medieval. Tesis doctoral dirigida por Pedro Sánchez-Prieto Borja. Universidad de Alcalá.
-
UEDA, H. (2013). “La función de la tilde en la grafía abreviada n del español medieval –Evidencias en los documentos notariales castellanos del siglo XIII al XV−”. En: Cuaderno de Instituto Historia de la Lengua, Año 4, Num.8. pp. 343-360.
-
UEDA, H. (2014). “Grafías dobles palatales en los documentos notariales del siglo XIII al XV−Sus implicaciones fonológicas y el origen de la letra española eñe”. En: Actas del Congreso Internacional sobre el español y la cultura hispánica. Instituto Cervantes de Tokio (2013), pp. 200-214.
-
VICENTE MIGUEL, I. (2009): “Aproximación al léxico de los tejidos y la indumentaria en documentos notariales medievales”, en L. Romero Aguilera, C. Julià Luna (coord.), Tendencias actuales en la investigación diacrónica de la lengua. En Actas del VIII Congreso Nacional de la Asociación de Jóvenes Investigadores de Historiografía e Historia de la Lengua Española Barcelona, del 2 al 4 de abril de 2008, 505-513.
-
VICENTE MIGUEL, I. (2006): “El léxico de la agricultura en documentos medievales de la catedral de Toledo (siglos XI a XIII)”. En Interlingüistica, 17,1058-1067.
|
Título del proyecto
|
Entidad financiadora / Participante
|
Duración
|
Investigador
responsable
|
Investigadores participantes
|
Cuantía (€)
|
|
Edición y estudio lingüístico de los fondos del Archivo Municipal de Guadalajara
|
Universidad de Alcalá
|
1992-1993
|
Pedro Sánchez-Prieto Borja
|
6
|
|
|
Documentos de la época de Sancho IV: edición y estudio
|
Universidad de Alcalá
|
1993-1994
|
Pedro Sánchez-Prieto Borja
|
6
|
|
|
Documentos medievales del Archivo Municipal de Toledo: edición y estudio lingüístico
|
Universidad de Alcalá
|
1996-1997
|
Pedro Sánchez-Prieto Borja
|
4
|
|
|
Documentos castellanos anteriores a 1700 RAE 27 / 96
|
Real Academia Española (Tipo de contrato: Art. 11 LRU) / Universidad de Alcalá
|
1996-1998
|
Pedro Sánchez-Prieto Borja
|
8
|
|
|
Gran corpus documental español de la Edad Media y de los siglos XVI y XVII (BFF2001-1041)
|
Ministerio de Ciencia y Tecnología / Universidad de Alcalá
|
2002-2005
|
Pedro Sánchez-Prieto Borja
|
6
|
|
|
Documentos de la antigua Inclusa en el Archivo Regional de la Comunidad de Madrid (edición y estudio Lingüistico) (CAM-UAH 2005/054)
|
Comunidad Autónoma de Madrid-Universidad de Alcalá / Universidad de Alcalá
|
E-D 2006
|
Pedro Sánchez-Prieto Borja
|
8
|
10.000
|
|
Edición y estudio lingüístico de los documentos medievales de la catedral de Toledo (HUM2006-04767/FILO)
|
Ministerio de Educación y Ciencia / Universidad de Alcalá
|
2006-2009
|
Pedro Sánchez-Prieto Borja
|
7
|
48.400
|
|
Documentos municipales conservados en el Archivo Regional de la Comunidad de Madrid (Edición y estudio lingüístico) (CCG06-UAH/HUM-0675)
|
Comunidad Autónoma de Madrid-Universidad de Alcalá / Universidad de Alcalá
|
2007
|
Pedro Sánchez-Prieto Borja
|
7
|
11.116
|
|
Edición y estudio lingüístico de documentos toledanos (siglos XVI y XVII) (FFI2009-10877)
|
Comunidad Autónoma de Madrid-Universidad de Alcalá / Universidad de Alcalá
|
2009-2012
|
Pedro Sánchez-Prieto Borja
|
6
|
29.040
|
|
Corpus de Documentos Españoles Anteriores a 1900: CODEA+2022 (FFI2012-33646)
|
Comunidad Autónoma de Madrid-Universidad de Alcalá / Universidad de Alcalá
|
2013-2022
|
Pedro Sánchez-Prieto Borja
|
9
|
47.000
|
|
Corpus de Documentos Españoles Anteriores a 1900: CODEA+2020 (FFI2017-82770-P)
|
Ministerio de Economía / Universidad de Alcalá
|
2018-2021
|
Pedro Sánchez-Prieto Borja
|
9
|
54.450
|
|
Desarrollo digital de corpus textuales: audios alineados
|
Comunidad de Madrid
|
2021
|
Pedro Sánchez-Prieto Borja, Mª del Carmen Fernández Líoez y Rocío Díaz Moreno
|
6
|
4.700
|
Una ventaja obvia de las fuentes documentales sobre los textos literarios, sobre todo para la Edad Media, es que aquellos están datados. Sin embargo, falta el año en 88 documentos.
Ante ello, Hiroto Ueda y Yosifumi Kawasaki, investigadores de este proyecto, han desarrollado una metodología que permite atribuir a estos documentos un año conjeturalmente, basándose en la comparación entre sus rasgos lingüísticos y los de los documentos fechados del corpus.
La aplicación a documentos con fecha ha permitido aquilatar el método: la desviación media comprobada es de 14 años. Esta datación propuesta se ha incorporado ya, pero el usuario podrá prescindir, si así lo desea, de estos documentos sin fecha explícita.
En la cabecera, la fecha obtenida conjeturalmente mediante la datación automática aparecerá entre corchetes.
El escribano, escribiente o autor material de la escritura se señala en la cabecera si está explícito en el documento. Su nombre va acompañado de la fórmula literal por la que indica su intervención, que también se ofrece en forma lematizada (en mayúscula; con verbos en infinitivo y en grafía actual):
0173 Diego Álvarez (HACER ESCRIBIR: lo fago escrivir)
La inmensa mayoría de los documentos indican de manera explícita el lugar de emisión. Los que carecen de él muestran con frecuencia por indicios muy fiables (ordenante, topónimos menores citados...) dónde fueron elaborados. En estos casos hemos atribuido una provincia conjetural.
Estos documentos pueden deseleccionarse en las consultas al corpus. En la cabecera, el lugar de emisión conjetural aparecerá entre corchetes.
El juego entre facsímil y transcripción paleográfica permitirá un mejor conocimiento de la historia de la escritura en la Península Ibérica. Es el caso de un fenómeno poco conocido como la escritura de -rr [*rr] en posición final de palabra en documentos navarros de los siglos XIII y XIV, y que podría considerarse indicio fonético. La historia de la lengua, por razones obvias, es seguramente el objetivo central.
El estudio de la sintaxis puede verse facilitado por la inclusión de presentaciones críticas con una puntuación cuidada, y por la búsqueda de colocaciones. No menos interés tiene el corpus para el estudio del léxico, por ejemplo para el concepto ‘venta’ [venta / vención / vendición / vendimiento].
Además, la rica clasificación tipológica de los documentos facilita el llevar a cabo estudios de diplomática. Por su contenido CODEA es una importante fuente de información para historia política y general, así como para la historia de las mentalidades y de la vida privada, sin olvidar la cultura material.
El valor antropológico y etnográfico del corpus es considerable. La riqueza en topónimos y antropónimos es uno de los puntos fuertes de la documentación archivística. CODEA puede además satisfacer las inquietudes del “curioso lector”, de cualquier persona interesada por el pasado lejano y reciente, o por la historia local.
Esta posibilidades tan variadas de aprovechamiento se ven incrementadas gracias a la rica información que proporciona la cabecera. Aquí puede verse un ejemplo:
|
Número de identificación del documento
|
0001
|
|
Grupo de investigación
|
GITHE
|
|
Corpus
|
CODEA+ 2022
|
|
Archivo y signatura
|
AMGU, 1H1.1
|
|
Fecha y lugar de emisión
|
1251 abril 13 (Sevilla, Sevilla, España)
|
|
Soporte y medidas
|
Pergamino, 346 x 391 mm.
|
|
Ámbito de emisión
|
Cancilleresco[/judicial/municipal/eclesiástico/privado]
|
|
Tipología documental y diplomática
|
Textos legislativos: carta plomada
|
|
Tipo de letra
|
Gótica documental
|
|
Escribano, fórmula lematizada y literal
|
Juan Pérez de Berlanga (FACERE: fecit)
|
|
Elaboración femenina
|
Emisor No, Firmante No, Escribiente No
|
|
Regesto
|
Carta plomada del rey Fernando III por la que confirma los fueros de Guadalajara, devuelve las aldeas que había segregado de su jurisdicción y establece normas sobre los hombres buenos enviados ante el rey, juez que lleva la “seña”, las cofradías, los alcaldes y los matrimonios.
|
|
Transcriptor/Revisor(es)
|
Pedro Sánchez-Prieto Borja
|
|
Palabras claves (10 máximo)
|
Concejo de Guadalajara, hombres buenos, caveros, aldeas, fuero, seña, cofradrías, alcaldes, bodas
|